Version: 1.9
Date: 2022-02-04
Authors: Paul Dickman, Vivekananda Lanka, Henric Winell, Rikard Öberg
Maintainer: [Object Analysis]
Table of Contents
Introduction
Computing servers offer a higher degree of parallelism and larger memory for computationally intensive tasks — but not necessarily higher speed — than standard PCs. This document contains the recommended procedures for computing server usage at MEB.
All servers are currently running under the Red Hat Enterprise Linux 7.9 operating system.
Matrix (matrix.meb.ki.se) is a compute server dedicated to applications SAS and Stata. It has 56 CPU threads, 768 GB of RAM and a very fast I/O disk card used for local temporary storage.
Vector (vector.meb.ki.se) is a compute server dedicated to computationally intensive operations with applications like R, PLINK, IMPUTE2, SNPTEST etc. (the complete list is on MEB IntraWeb). It has 144 CPU threads and 1.5 TB of RAM.
Scalar (scalar<1-4>.meb.ki.se) is a set of SLURM compute nodes using Vector as the login node. All nodes have the same applications as Vector. Each node has 40 CPU threads and 320 GB of RAM.
Getting an account
If you believe that your project may benefit from running applications on the computing servers, fill out an account request on the MEB IntraWeb. For futrther information, please contact the Analysis Object Maintenance Manager (currently Henric Winell).
The user credentials for the computing servers are the same as the MS Windows login.
Usage guideline
In keeping with the MEB philosophy of “freedom with responsibility“, we have not implemented centralized restrictions on CPU hours or memory usage. A consequence of this approach is that the users themselves must be aware of the amount of system resources in use and structure their work so that everyone can use the shared resources effectively.
All users of these resources are required to use the servers efficiently and show maximum consideration for other users. This includes, but is not limited to
- Reading this document before starting jobs on the servers.
- Checking system availability, CPU load and RAM usage before starting new jobs.
- To avoid resource conflicts, notify other users through meb-matrix@emaillist.ki.se and meb-vector@emaillist.ki.se, respectively, well ahead of time when planning to use the servers during nights and weekends.
- It is recommended to notify other users if you plan to use more than10 threads for an extended period of time (8+ hours).
- It is recommended to notify other users if you plan to use more than 100 GB of RAM for an extended period of time (8+ hours).
- It is recommended to use the SLURM queue system from Vector to handle long running jobs (see the section on SLURM in this guideline for more information).
- Remove files that are no longer needed.
- Disconnect/logout when not using the server for computations. This applies to, e.g., SSH or VDI connections as well as obsolete screen or #tmux sessions (see the section on #tmux in this guideline for more information).
- Large file or storage (100+ GB) requirements need to be planned well ahead of time and together with MEB IT Support.
If the system stability is compromised, MEB IT Support may stop processes and remove files.
Application behavior
SAS
SAS is I/O intensive and operates against the file system SASWORK. This may require users to monitor SASWORK, which has a quota limit of 150 GB per user. The quota is to avoid SASWORK to become full for all other SAS users. CPU and RAM usage is usually not an issue when working with SAS.
Read more about how to use SAS and for tips on efficient programming here.
Stata
Stata/MP is both CPU and RAM intensive, but this is usually not an issue if you are running a single instance. Running several instances require you to monitor CPU and RAM usage.
R
R is CPU intensive and can allocate large amounts of RAM. This is particularly the case for parallel operations using non-shared memory, e.g., when using parallel::parLapply() on a local PSOCK “cluster”. We therefore recommend a shared-memory approach, e.g., by setting up a local FORK “cluster” for use with parallel::parLapply() or using parallel::mclapply(). See package parallel‘s documentation for more information on parallel operations in R.
Starting with R version 3.6.1, support for add-on packages requiring C++14 or higher has been added. However, this is not enabled by default. To start R with the support enabled, issue scl enable devtoolset-8 R at the Bash prompt. To permanently enable the support in the Bash shell, add source scl_source enable devtoolset-8 to your ~/.bashrc file, log out and log in again.
Other applications
I/O intensive applications or, e.g., repeated processing of large files during computations, may benefit if used under the scratch file system located at /scratch/tmp[^1]. This is due to the home (/nfs/home) and project folders (/nfs/projects) being situated on the NFS storage system, which runs slower (and generates a lot of backup traffic during nights). However, note that /scratch/tmp is intended for temporary storage only and that files and folders older than five days will be deleted automatically.
How to use the servers
Connection
Connect/logon to the servers is made through a secure shell (SSH) connection. Under MS Windows, the current recommendation is to use KiTTY as the SSH client together with the WinSCP file manager for drag-and-drop of files and folders. Under macOS, an SSH connection can be started in a terminal window.
File systems
Home folders
Home folders are located under /nfs/home/\ and have quota limits of 100 GB per user. The home folders are shared between the servers.
Scratch
Scratch is a local file system intended for I/O intensive temporary storage. Users need to create their own temporary folders under /scratch/tmp/<username>.
Files and folders on the scratch disk will be automatically deleted when their modification time exceeds five days. The scratch file system has a quota limit of 500 GB per user.
SASWORK
SASWORK is a fast local temporary space intended for SAS and is therefore only available on Matrix. The /saswork/tmp file system has a quota limit of 150 GB per user. For SAS users requiring more disk space, we recommend using the scratch disk (possibly in combination with SASWORK if necessary).
STATATMP
Analogously to the above, STATATMP is a fast local temporary space intended for Stata.
Project folders
Project folders are located under /nfs/projects and contain folders that are typically shared between several researchers working in cooperation. Project folders have quota limits between 10 GB-1 TB and are shared between the servers.
Some projects, usually when exceeding 1 TB, have their own file systems directly under /nfs/<projectname>. Group access to specific project folders are granted by their respective owners.
Windows drives Z: and P:
The MS Windows drives Z: and P: can be accessed via /cifs/Z and /cifs/P. However, in order to do so you may be required to initiate a so-called Kerberos ticket. This is done by evoking the UNIX command kinit; if you have not setup GSSAPI integration in your favorite SSH client before logon to the server, provide your password when prompted. Kerberos tickets can be checked by issuing the UNIX command klist.
However, do not work directly against these folders since the Kerberos ticket can expire during job execution causing Z: and P: to be inaccessible. Instead, copy the desired files and folders to the scratch disk (and back, if necessary, when the job is done).
File creation
All program and data files should be prepared on your local computer if possible, including testing and debugging with reduced data size.
Please, do not experiment on the servers!
File transfer
Files can be transferred to or from the server via the secure file transfer protocol (SFTP). If desired, this can be done through a graphical user interface, e.g., WinSCP under MS Windows.
Depending on your operating system and setup, command-line tools, like sftp and scp, can also be used.
Running programs
Once all data and command files have been copied to the server, the user needs to start their program from the server’s command line. This is done via the SSH protocol. Under MS Windows, we (again) recommend using KiTTY.
tmux
tmux is a terminal multiplexer, i.e., a program that can be used to run applications interactively while being able to disconnect from the server and resume the session at another time. However, it is important that tmux sessions are ended when they are no longer useful, e.g., when the job has been finished.
- Start the tmux session via UNIX command
tmux. - Run your program.
- Detach from tmux by pressing
Ctrl + b d. - Reconnect to tmux using
tmux attach. - To end a tmux session permanently press
Ctrl + dwhile in tmux. - Check if you have ongoing tmux sessions with
tmux ls.
SLURM
The SLURM workload manager can submit jobs to a queue that performs the jobs on the Scalar nodes instead of interactively on the Vector node. The queue system will make sure to run the jobs without overloading the system running too many jobs simultaneously regarding CPU threads memory and ends jobs that are running to long time. The queue system does not know how many CPU threads your job eventually will use for the parallelization / subtasks so make sure to specify the number of CPU threads anticipated.
Example to submit a job a simple one-task job: Create a shell script <filename>.sh with the code you want to execute. For example,
#!/bin/bash
echo "hello world"
sleep 60Submit <filename>.sh to the queue using
sbatch <filename>.shThe default time and memory limits per job are currently set to 240 minutes and 4.8 GB, respectively. To submit a job that you know will use a maximum of 4 CPU threads and 10 GB of RAM and will be finished within max 8 hours (480 minutes)
sbatch --ntasks 4 --time 480 --mem 10000 <filename>.shTo submit jobs on specific SLURM nodes add --nodelist <nodename(s)>. Submitting jobs excluding specific SLURM nodes can be done by adding --exclude <nodename(s)>. For example,
sbatch --nodelist scalar3,scalar4 <filename>.shwill run the jobs on the scalar3 and scalar4 nodes. To run interactively on one of the SLURM nodes use srun. For example,
srun --nodelist scalar4 --pty bashYou can also specify the sbatch information within the shellscript using example:
#SBATCH --ntasks 4
#SBATCH --time 480
#SBATCH --mem 10000
#SBATCH --nodelist scalar3,scalar4To see state of the SLURM system run sinfo.
To see the SLURM job queue run squeue.
To see information about a job run scontrol show job <jobid>.
To cancel running jobs use scancel <jobid>.
To cancel all your jobs (running and pending) use scancel --user <username>.
The Scalar nodes have access to the same NFS areas (/nfs) as Vector. They also have a /scratch/tmp area but it is not shared with Vector’s /scratch/tmp. Hence, you need to create your own folder/files there from within your sbatch script.
If you use the SLURM queue you have to keep in mind that /scratch/tmp is local to each of the Scalar nodes.
Clean up
Transfer the results to your local computer via, e.g., SFTP as above, and delete the files no longer needed on the server.
For long-term storage of files, we recommend the MS Windows fileserver (P: or Z: drive). Ask MEB IT Support if more space is required on the fileserver.
Things you may find useful when working on the servers
Some UNIX commands
htop displays all user processes (sorted by CPU usage by default). Press
h for help or q to quit.
Pressing M (i.e., Shift + m ) while in htop will sort by memory usage per process. Analogously, pressing P (i.e., Shift + p ) will sort by CPU usage.
htop --u <username> displays only processes belonging to \ in the same way as above.
Alternatively, the older top can be used instead of htop. See below for an example running top.
du --hs ~ will report how much space your home folder is occupying.
du --hs /<foldername>/* will report how much disk space files and folders occupy within \.
df --h will report file system usage, e.g., how large and how full the /nfs/home, /saswork and /nfs/projects file systems are.
uptime can be used to check the current load averages on the system for the past 1, 5 and 15 minutes.
free --g can be used to check the total amount of free and used RAM in GB.
kill <processid> can be used to stop a process; the process id number can be found in the PID column in top. Note that processes can also be killed from top and htop.
If you want to redirect e-mail that you receive on the server (e.g., about finished batch jobs) to a different e-mail address, you can change the address in the .forward file in your home directory. You can change this file either in a text editor, e.g., vi, or directly from the command line via the following command:
echo firstname.lastname\@ki.se > ~/.forwardExample output from top
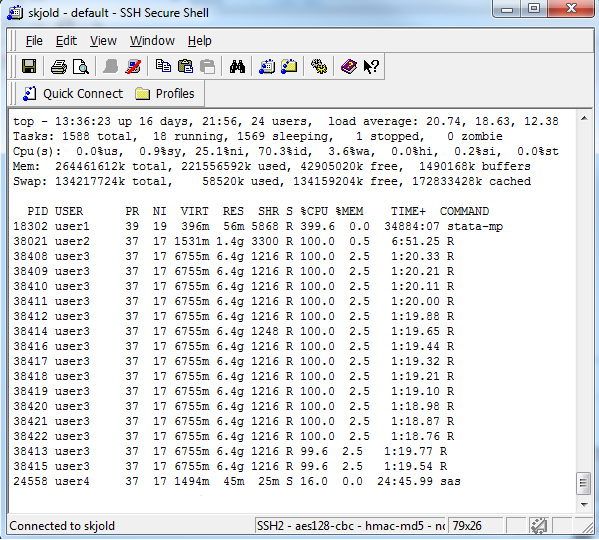
In the upper right corner, the load average on the server for the past 1, 5 and 15 minutes is shown. In this example, we can see that the server has been using 20.74 threads over the past minute. So, if Matrix
and Vector have average loads of 56 and 144, respectively, all CPU threads are fully utilized. No new jobs should be started when the load average reach 52 and 140 threads, respectively.
The Mem: row shows the total amount of memory used and how much is free in kB, so in this example 42 GB is free.
The PID column shows the process identity number. A process can be stopped from the command line with kill \. The %CPU column shows the percentage CPU load per process that are currently being executed and who is executing it by looking in the USER column. The RES and %MEM columns show the actual and percentage amount of RAM, respectively, each process is consuming (g = GB, m = MB); note that processes consume RAM even if they sleep, i.e., when their CPU utilization is 0 %.
In this example, user1 is running a single Stata/MP process using four CPU threads (%CPU 399.6) and 56 MB RAM, user2 runs an R process using a single thread (%CPU 100.0) and 1.4 GB RAM, and user3 runs fifteen R processes (each %CPU 100.0) and using a total of 96 GB RAM).
[^1]: Each user is required to create their personal folder on scratch,
i.e., /scratch/tmp/\<username>.